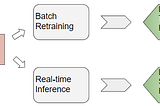
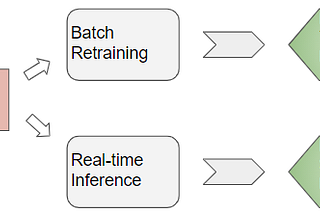
Ketan DoshiinTowards Data ScienceEnterprise ML — Why getting your model to production takes longer than building itThe complexities of model deployment, and integrating the application/data pipeline. What the Data Engineer, ML Engineer, and ML Ops do.Jun 28, 20213Jun 28, 20213
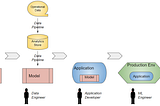
Ketan DoshiinTowards Data ScienceEnterprise ML — Why building and training a “real-world” model is hardA Gentle Guide to the lifecycle of a Machine Learning project in the Enterprise, the roles involved and the challenges of building models…Jun 17, 2021Jun 17, 2021
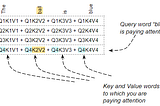
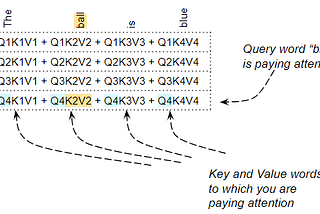
Ketan DoshiinTowards Data ScienceTransformers Explained Visually — Not just how, but Why they work so wellA Gentle Guide to how the Attention Score calculations capture relationships between words in a sequence, in Plain English.Jun 2, 202124Jun 2, 202124
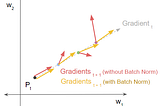
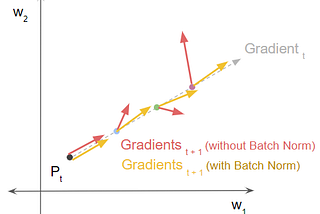
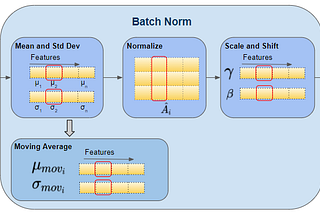
Ketan DoshiinTowards Data ScienceBatch Norm Explained Visually — Why does it workA Gentle Guide to the reasons for the Batch Norm layer’s success in making training converge faster, in Plain EnglishMay 26, 20211May 26, 20211
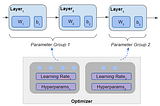
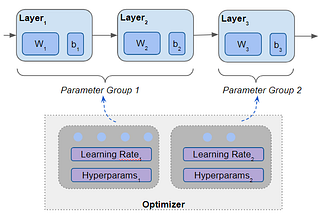
Ketan DoshiinTowards Data ScienceDifferential and Adaptive Learning Rates — Neural Network Optimizers and Schedulers demystifiedA Gentle Guide to boosting model training and hyperparameter tuning with Optimizers and Schedulers, in Plain EnglishMay 23, 20211May 23, 20211
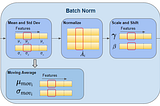
Ketan DoshiinTowards Data ScienceBatch Norm Explained Visually — How it works, and why neural networks need itA Gentle Guide to an all-important Deep Learning layer, in Plain EnglishMay 18, 202113May 18, 202113
Ketan DoshiinTowards Data ScienceFoundations of NLP Explained — Bleu Score and WER MetricsA Gentle Guide to two essential metrics (Bleu Score and Word Error Rate) for NLP models, in Plain EnglishMay 9, 202110May 9, 202110
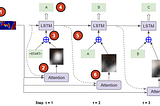
Ketan DoshiinTowards Data ScienceImage Captions with Attention in Tensorflow, Step-by-stepAn end-to-end example using Encoder-Decoder with Attention in Keras and Tensorflow 2.0, in Plain EnglishApr 30, 20216Apr 30, 20216
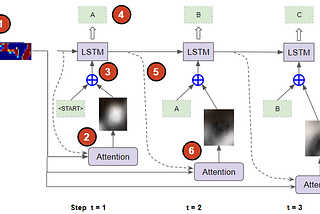
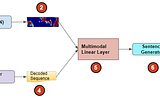
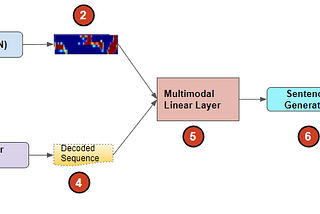
Ketan DoshiinTowards Data ScienceImage Captions with Deep Learning: State-of-the-Art ArchitecturesA Gentle Guide to Image Feature Encoders, Sequence Decoders, Attention, and Multi-modal Architectures, in Plain EnglishApr 23, 20213Apr 23, 20213
Ketan DoshiinTowards Data ScienceLeveraging Geolocation Data for Machine Learning: Essential TechniquesA Gentle Guide to Feature Engineering and Visualization with Geospatial data, in Plain EnglishApr 17, 20216Apr 17, 20216